We thought the hard part was getting a LangChain agent to book hotel rooms over WhatsApp. It wasn't — it was discovering that 5% of conversations were burning 45% of our token budget, and that "just tell the model not to leak PII" is not a strategy.
What We Actually Shipped
Not a "Book me a room in Goa" demo. The primary booking and guest-ops interface for hundreds of properties — resorts, homestays, small hotels — running on WhatsApp, handling hundreds of concurrent conversations on peak weekends. Guests discovered a property, checked dates, confirmed pricing, paid, and received check-in instructions, all in one thread. The product was growing when the investment runway ended, so these are lessons from a live system serving real guests, not a polished retrospective. If you're shipping something similar, most of this will sound familiar or will soon.
Two commercial models ran simultaneously. Subscription properties paid a low monthly subscription by room count, unlimited conversations. Pay-as-you-go properties used the platform free and paid a single-digit percentage commission per booking. The economics of every conversation were fundamentally different depending on which model a property was on. That distinction came back to bite us.
On the supply side, we integrated with cloud PMSes (AxisRooms, eZee Centrix, a couple of niche regional ones) and a thin internal API wrapper for owners who only had OTA extranets and spreadsheets. We periodically refreshed availability and cached it locally. Live PMS calls only happened at the point of booking. No full two-way sync — that way lies madness — but if cached availability had drifted by the time a guest confirmed, the system flagged it rather than silently booking stale inventory.
The bot handled four types of conversations: availability and pricing queries ("pool and breakfast under ₹4,000/night, approximately $48?"), booking confirmation (collect details, send payment link, push to PMS), post-booking ops (check-in changes, extra beds, directions), and everything else ("best cafes nearby", "airport pickup?"). For each property, this wasn't an experiment. This was their direct-booking channel.
The First Attempt: Everything Inside n8n
Before LangGraph, we tried building the entire agent as an n8n workflow. 70+ AI nodes, visual chains, 4–7 LLM calls chained in series per guest message. P50 latency sat at 8–10 seconds, P95 at 15–20 seconds. On WhatsApp, anything past 4 seconds and guests assume it's broken and resend, which spawns parallel workflows and makes things worse.
We ran this for four weeks, then did a two-week A/B against the LangGraph rebuild. LangGraph brought P50 down to 3–5 seconds, P95 to 8–10 seconds. Over 2x improvement at the median.
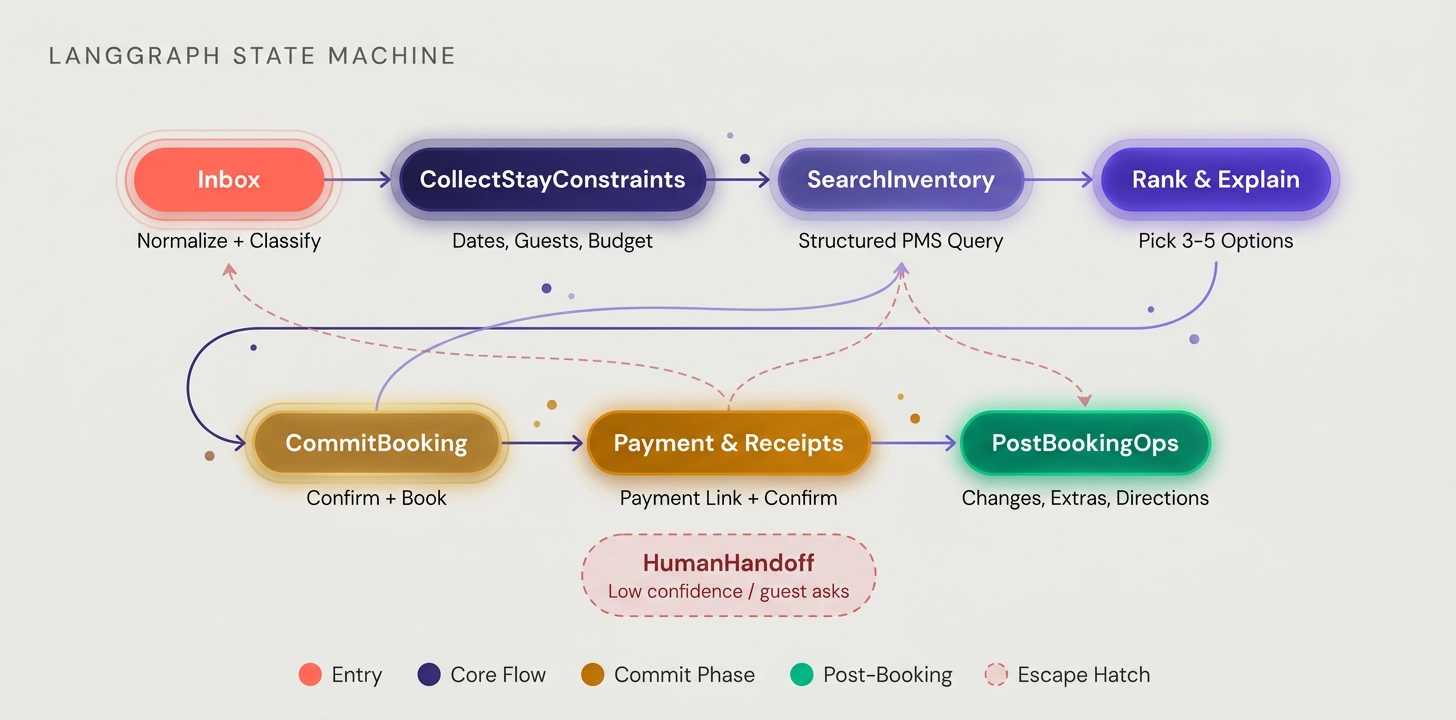
Agent Architecture: LangGraph State Machine
We rebuilt around eight operational states: Inbox (normalize and classify), CollectStayConstraints (dates, guests, budget, amenities), SearchInventory (structured PMS query from state, not free-form LLM text), RankAndExplainOptions (pick 3–5 grounded options), CommitBooking (confirm and book), PaymentAndReceipts, PostBookingOps, and HumanHandoff (when confidence is low or the guest asks). The model still decided things like classification and ranking, but what it was allowed to do at each step was locked down by the graph.
The Cost Surprise Nobody Planned For
Our back-of-the-envelope calculations assumed 3–4 turns per booking, 500–700 tokens. Here's what actually happened.
Median conversations sat under 1,000 tokens (excluding a large cached system prompt, cached via Gemini at a 90% discount). Fine. But the 90th percentile was 3–4x that. The 99th hit 20–30x. The top 5% of conversations consumed 35–45% of all tokens. The top 1% alone ate a low-teens share of total spend.
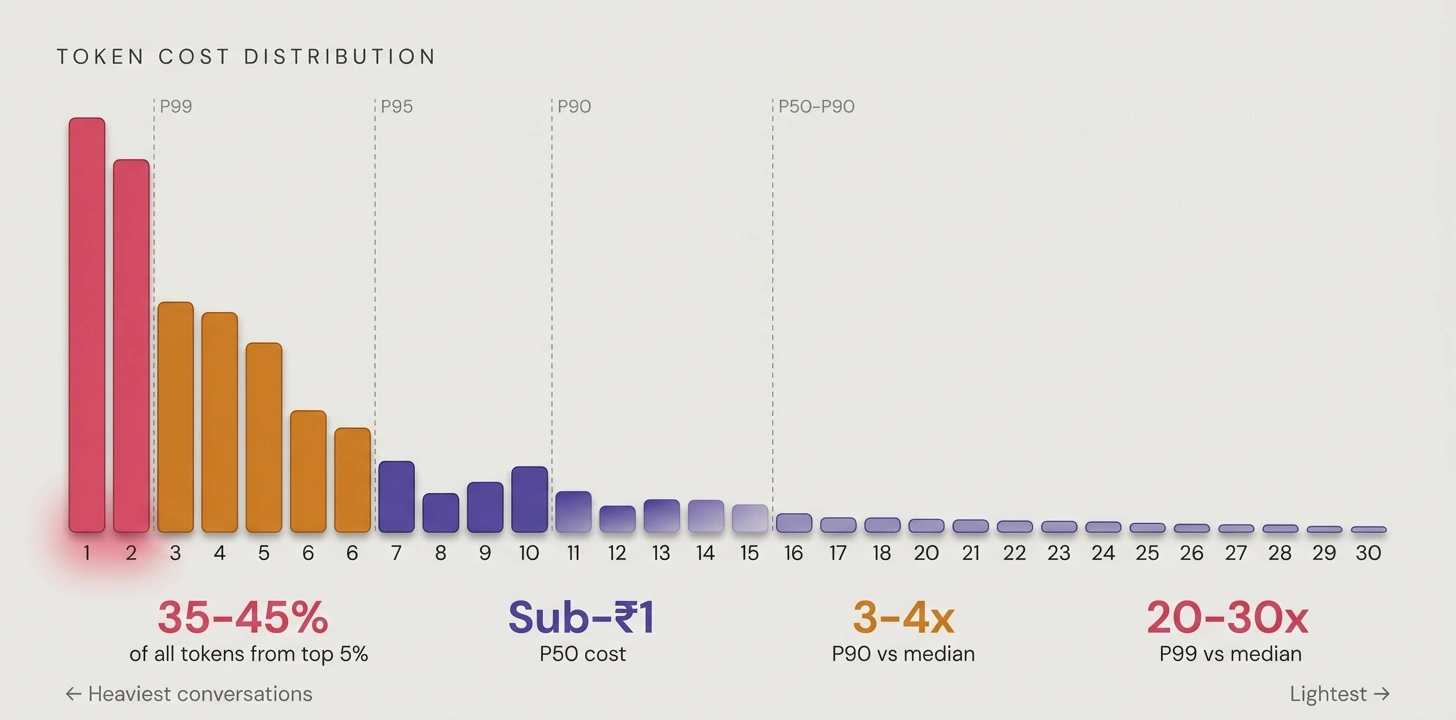
Three types of guests drove this: people who asked 15–20 questions about local sights and then ghosted without booking; properties with thin margins where 10–15 long messages flipped the economics; and complex multi-room requests that needed several availability and pricing passes.
The Numbers
We started on Claude Haiku 3 for all nodes, then moved to Haiku 3.5 when it launched. Both were fast and cheap. But when we ran structured evaluations — comparing intent classification accuracy, constraint extraction completeness, and ranking explanation quality against cost per correct response — Gemini consistently won on the metric that mattered: correct output per dollar. Haiku 3.5 was marginally better on reasoning for our ranking node, but Gemini 3 Flash matched it at lower cost, and Flash-Lite handled classification at a fraction of either. The migration took a week of parallel evaluation on sampled production traffic and two days of integration work.
After optimization — tiered model routing with lightweight models for classification and higher-capability models for reasoning, system prompt cached across both — per-conversation cost was sub-rupee at the median, scaling steeply at P99. Someone treating the bot as a personal travel concierge for 20+ turns could cost 20–30x the median.
Individually trivial. At property scale, not trivial at all.
Why the Two Commercial Models Made This Worse
Subscription properties paid a fixed monthly fee. Every conversation was our cost to eat. Baseline LLM spend was manageable, but spiked 3–4x on engaged properties where guests asked about treks, restaurants, and festivals — pushing 20–25 conversations into P90 territory and 5–10 into P99. On the worst properties, 30–50% of subscription revenue burned on inference alone, before counting infra or WhatsApp API costs.
Pay-as-you-go properties paid nothing until a booking happened. At a 15% conversion rate, the amortized LLM cost per booking was a rounding error against commission revenue. At 5% conversion on a chatty property, per-booking LLM cost spiked to a level approaching OTA commission rates — which was exactly what our zero-commission pitch was supposed to avoid.
Per-Property P&L Changed Everything
We tagged every LLM call with per-request metadata tagging (property, conversation, pipeline stage), piped it through Langfuse, and joined it with booking revenue. Three patterns emerged:
Healthy properties — decent ADR, good conversion. LLM cost was noise. Subscription traps — beloved by guests, deeply unprofitable for us. The fix: restructure tiers so pricing reflected conversation volume, not just room count. Conversion sinkholes — high chat volume, low bookings. The fix: behavioral guardrails that steered exploratory conversations toward commitment rather than open-ended concierge mode.
That P&L dashboard became more important than any feature we built. It was the first time we could see which properties were profitable.
Retrieval Failures Real Guests Exposed
Retrieval looked fine in testing. Then real guests showed up. The failures weren't silent — guests told us, often loudly and in their language of choice.
Multi-intent queries:
"Need 2 rooms in North Goa next weekend, one for 3 adults, one for 2, both with breakfast and parking, walking distance to beach, under ₹5,000/night (approximately $60). Free cancellation?"
The system latched onto "North Goa" and "parking", returned a generic list, and made up free cancellation. It ignored occupancy splits and the budget cap entirely. The retriever was treating constraints as soft hints in the vector query when they needed to be hard filters against the PMS.
Fix: Moved multi-intent parsing into CollectStayConstraints with hard filters against the PMS, semantic ranking only on already-valid results.
Cross-session references:
"Show me that cottage you sent yesterday in Coorg, the one with bonfire and no pets, but for next month's long weekend."
State only lived within a session. The system ran a fresh search, found a different Coorg property, and confidently said "this is the one I showed you."
Fix: Conversation memory index. Every time we surfaced options, we stored compact snapshots (property, dates, price, constraints) keyed by conversation. Referential queries checked there first.
Testing: From Eyeballing to DeepEval
For the first few weeks, testing meant typing messages and checking if the response looked right. That catches obvious problems and misses everything that matters.
DeepEval gave us actual automated evaluation. G-Eval criteria for individual LangGraph nodes (intent classification accuracy, constraint extraction, hallucination checks on tool responses), running in pytest as CI gates. 65+ integration tests covering happy paths, edge cases, and specific failures we'd already seen in production. We didn't run the full suite on every commit — too slow. Only release candidates. That tradeoff mattered: fast component tests caught regressions early, the full suite caught the subtle stuff before it shipped.
Production monitoring closed the loop: weekly sampled traces run through batched DeepEval, combined with Langfuse per-property tracing to catch where quality was drifting, not just that it was.
If you're still testing prompts by hand, the drift will find you before your users tell you. Testing Conversational AI in Production — coming soon.
PII: Infrastructure, Not Prompts
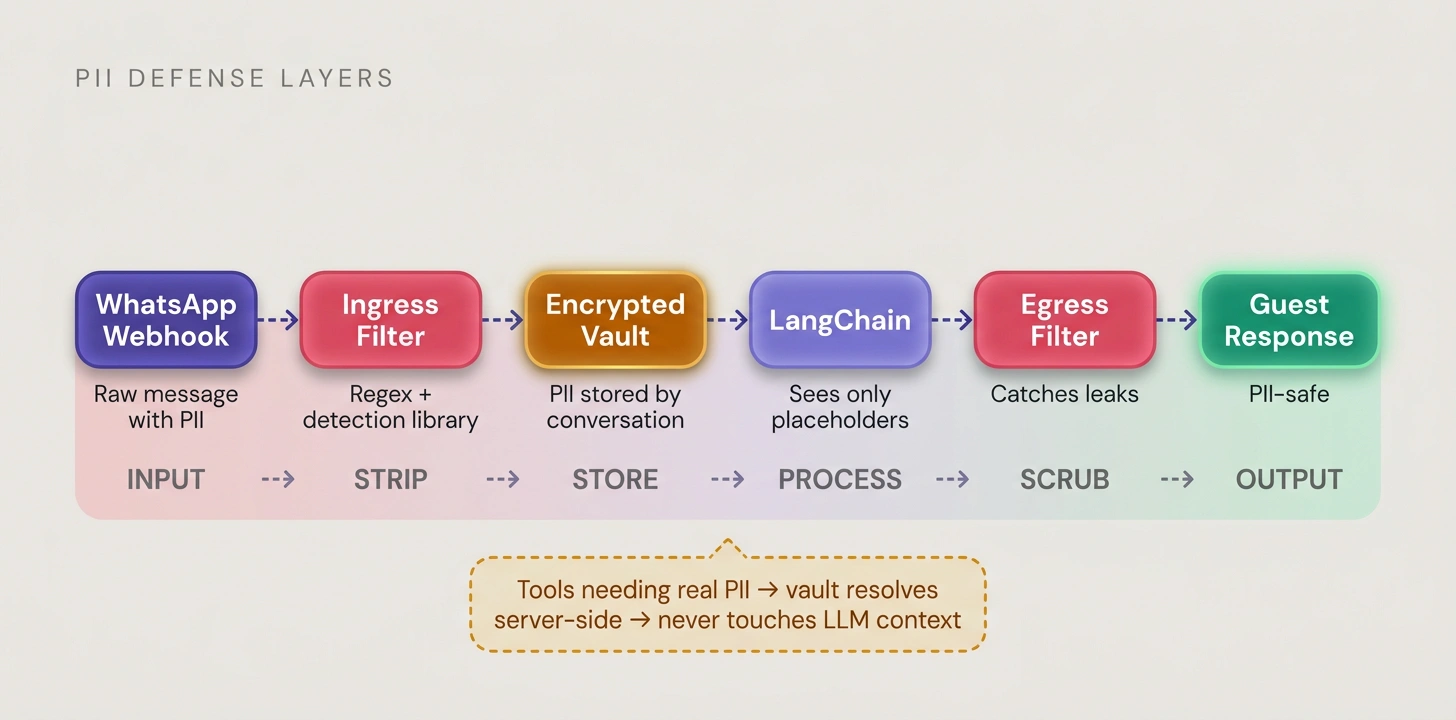
"Just tell the model to never reveal PII" was our first instinct and it was wrong. The real risk wasn't the LLM leaking something in a response. It was multi-party communication: guests sharing UPI IDs with managers, managers sharing personal payment details with guests, support agents accessing conversations. All of it needed masking in real time.
We treated PII as plumbing: ingress filter at the webhook (regex + detection library) stripped PII before anything reached LangChain. Encrypted vault stored it keyed by conversation and guest. The model only saw placeholders. Tools that needed real PII resolved them server-side. Egress filter caught leaks before delivery. Langfuse traces were already scrubbed at ingestion.
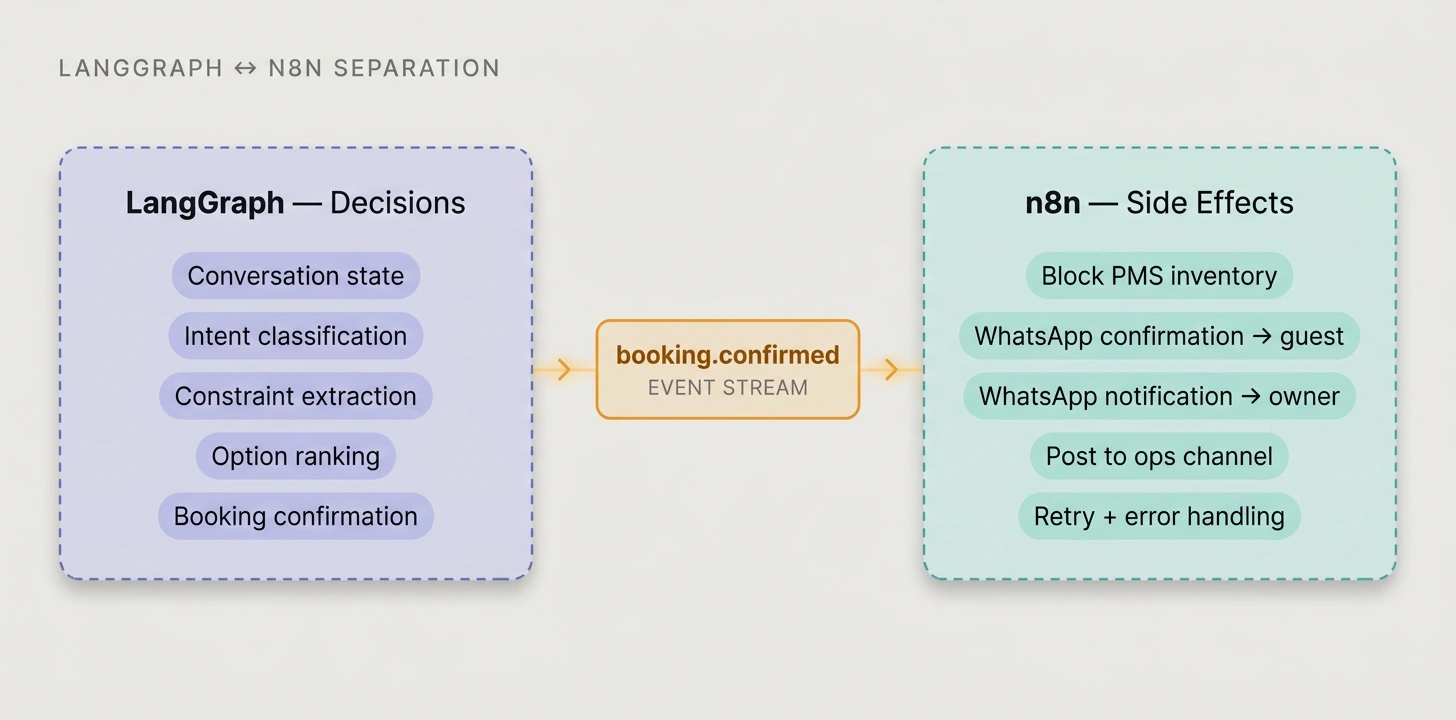
n8n as Side-Effect Layer
Making the agent handle every integration turned the graph into mud. One bad webhook retry loop held up a guest's booking confirmation for 40 minutes while n8n would have retried and moved on in seconds. So we carved out side-effects: on a booking.confirmed event, n8n blocked PMS inventory, sent WhatsApp confirmations to guest and owner, and posted to the ops channel. LangGraph owns conversation state. n8n owns what happens after decisions are made.
What This Teaches
The gap between demo and production is never the model. It's everything else.
Tag every LLM call for cost attribution from day one. Per-tenant economics were invisible until we had per-property, per-stage tagging. The top 5% of conversations eating 35–45% of tokens was a number nobody saw coming.
Filter before you rank. Semantic search on its own looked great in staging. Real guests brought multi-intent queries, budget caps, and occupancy constraints that needed hard filters against the inventory system, not soft hints in a vector query.
Automate evaluation before the first deploy. 65 test cases and a 15-minute suite on RC builds gave us the confidence to actually ship changes. Without it, every prompt tweak was a coin flip.
Treat PII as plumbing, not prompting. Multi-party communication needs ingress filtering, encrypted vaults, placeholder contracts, and egress scrubbing. The LLM is the least important layer.
Separate decisions from side-effects. Agent emits events, workflow engine handles the rest. Collapsing both was our most expensive mistake.
If you're about to ship, start here:
- Where will per-tenant cost and quality be observed, and who sees those numbers weekly?
- What's your non-AI backbone for everything the agent can't or shouldn't do?
- What does your evaluation pipeline look like before the first production deploy?
Only after those are answered do we talk about models.
Content on this page may not be reproduced, distributed, or republished without prior written permission. Sharing links is encouraged. See our Terms of Use for details.